https://www.inflearn.com/course/ORM-JPA-Basic 을 공부하며 정리한 글입니다.
JPA의 등장배경
JPA는 sql을 하나하나 작성하지 않고도 데이터베이스에 CRUD 작업이 가능하도록 하고 무엇보다 객체적인 설계와 데이터베이스 모델링의 차이를 없애주기 위해서 등장했다. 이 JPA를 사용함으로써 객체를 컬렉션에 저장하듯이 저장하는 것이 가능하다.
객체적인 설계와 DB 모델링의 차이라고 하면 객체에서는 다른 객체에 대한 참조값을 지니게 되지만 디비 세상에서는 그런게 없다... 다른 테이블의 외래키를 들고 있을 뿐이다. 데이터 베이스 모델링대로 코딩하면 다음과 같이 된다는 말이다.
//객체 모델링
class Student {
private School school;
private String name;
//getter setter 생략
}
//데이터베이스에 맞춘 모델링
class Student {
private int schoolId;
private String name;
//getter setter 생략
}아래와 같이 코딩하는건 너무 객체지향스럽지 않다.. ㅋㅋㅋㅋㅋㅋㅋ 여기에 상속 개념도 디비에 어떻게 적용해야하나를 생각해보게 되면 상당히 복잡해진다. 그리고 객체를 컬렉션에 저장하듯이 라는 말은 뭘까? 데이터를 프레임워크에서 꺼내오는 상황을 생각해보자. ArrayList 에서 Student 하나를 가져와서 setName을 통해 이름을 바꿨다. 그러고 다시 ArrayList에 집어넣나?? 절대 아니다. ArrayList는 자신이 들고있는 객체들의 실제 데이터가 아닌, 참조값을 가지고 있을 뿐이고 때문에 우리는 ArrayList로 부터 꺼내온 주소값에 접근하여 name 필드값 자체를 바꾼것이다. 그러니 다시 ArrayList에 집어넣는건 말이 안되는 것이다. 이제 이걸 데이터베이스로 생각해보면 select 문을 날려서 값을 가져오고, 어떤 로직을 수행한 후 변경된 값을 update 쿼리를 통해 날려서 수정해줘야한다. 이런 과정들을 JPA는 엄청 쉽게 할 수 있도록 도와준다. 지금까지 소개한 두가지 이슈를 JPA는 어떻게 해결하고 있는지 정리해봤다.
영속성
이미 이름부터가 Java Persistence API 라는 거에서부터 알 수 있듯 영속성은 JPA를 공부하는데에 있어서 핵심적인 개념이다. @Entity 어노테이션을 닮으로써 JPA가 관리하게 되는 엔티티들은 영속, 준영속, 비영속, 삭제 생명주기를 가진다.
public static void main(String[] args) {
EntityManagerFactory emf = Persistence.createEntityManagerFactory("hello");
EntityManager em = emf.createEntityManager();
EntityTransaction tx = em.getTransaction();
tx.begin();
try {
// =======
// 로직 수행
// =======
tx.commit();
} catch (Exception e) {
tx.rollback();
} finally {
em.close();
}
emf.close();
}1. 비영속
코드에서 new 연산자를 통해 엔티티 객체를 하나 생성한 상태를 비영속이라고 한다.
2. 영속
em.persist(객체) 를 통해서 객체를 영속성 컨텍스트에 저장하게 되면 이를 영속 상태라고 한다.
3. 준영속
em.detach() 준영속 상태는 영속성 컨텍스트에서 엔티티를 분리한 상태이다.
4. 삭제
em.remove() 를 통해 객체를 삭제한 상태.
비영속과 준영속의 차이는 뭘까??
일반적으로 구글링을 통해 알아낼 수 있는 비영속과 준영속의 차이는 식별자 값이 있고 없고의 차이 혹은 비영속은 식별자가 없을 수도 있지만 준영속은 식별자가 있다! 처음엔 이게 무슨 소리인가 싶었다. 이를 차근차근 설명해보자면 식별자 값이란 디비에 저장되었을때 pk 값을 얘기한다. 코드를 통해 예를 들어보면
class Member {
@Id @GeneratedValue
private Long id;
}위 Member 클래스의 id가 식별자인 것이다. 그렇다면 식별자가 있을수도 있고 없을수도 있다는건 단지 setID 등의 setter를 통해서 생성한 객체의 id값을 세팅했냐 안했냐이다. 영속성 컨텍스트에 저장되기 위해서는 식별자 값을 가지고 있어야 하므로 "있을수도 있고 없을수도 있다" 라는 것이다. (@GeneratedValue 어노테이션으로 인해 식별자인 id 필드는 자동으로 초기화된다) 조금 더 명확하게 결론내려보자면 비영속과 준영속의 차이는 영속성 컨텍스트에서 관리된 적이 있냐 없냐 이다.
em.persist() 를 호출한다고 해서 바로 디비에 실제 insert문 쿼리가 날라가서 저장되는 것이 아니다. em.persist를 하게 되면 영속성 컨텍스트 내에 1차 캐시에 저장되고 insert 문은 '쓰기 지연 SQL 저장소'에 등록된다. 쓰기 지연 저장소에 모인 SQL들은 플러시가 발생하면 데이터베이스에 일괄적으로 전송된다.
플러시가 발생하는 경우는 다음과 같다.
1. em.flush() 를 통한 직접 호출
2. tx.commit() 을 통해 트랜젝션이 커밋될때
3. JPQL 쿼리가 실행될 때
3번은 왜 발생하냐하면 만약 em.persist() 로 객체를 3개 저장하고 JPQL로 select 문을 실행했다고 생각해보자. 만약 3번이 없다면 아직 쓰기지연 저장소에 insert 문들이 남아있는 상태이므로 실제 DB에는 아무런 데이터가 없는 상황이다. 그러므로 영속성 컨텍스트에 저장했음에도 불구하고 JPQL의 select문의 결과는 텅 빈 배열이 반환될 것이다. 이런 상황을 방지하기 위해 JPQL 쿼리가 실행되면 그 직전에 플러시가 발생한다.
플러시와 1차 캐시
여기서 중요한것은 플러시가 발생한다고 해서 1차 캐시가 비워지는 것은 아니다. 단지 쓰기 지연 저장소에 있던 쿼리문들이 실행될 뿐이다. 1차 캐시를 비우기위한 함수는 다음과 같다.
- em.detach() : 특정 엔티티만 분리한다.
- em.clear() : 1차 캐시를 비워준다.
- em.close() : 영속성 컨텍스트를 종료한다.
영속성 컨텍스트 - 1차 캐시, 더티체킹, 동일성 보장
저장에는 persist가 있었다면 검색을 위한 함수로는 find가 있다. em.find() 을 호출하면 가장 먼저 1차 캐시를 찾아본다. 1차 캐시에 찾는 데이터가 없다면 디비로 select 문을 날려서 결과를 가져오고 1차 캐시에 저장한다.

1차 캐시에는 더티체킹 (변경 감지)를 위해서 스냅샷을 남긴다. find로 데이터를 찾아왔을 때나 persist로 데이터를 처음 저장했을 때에 스냅샷에 데이터가 남는다. 이후에 만약 setter를 통해 값을 변경하고 이후에 플러시가 일어나게 되면 영속성 컨텍스트에서는 엔티티의 값과 스냅샷의 값을 비교하여 update 구문을 만들어서 디비에 날려준다.

18번 줄에서 persist를 하면 1차캐시에 저장됨과 동시에 쓰기지연 저장소에 insert 문이 저장되고 setName을 하게되면 엔티티값을 변경한다. 그래서 이후에 플러시가 일어나면 변경을 감지하여 update 문을 만들고 순차적으로 insert update 쿼리가 나가게 되는 것이다.
영속성 컨텍스트에서는 동일성을 보장해준다. 이는 한 트랜젝션 내에서 동일한 객체를 찾으면 모두 == 연산을 했을때 true가 나온다는 것이다.
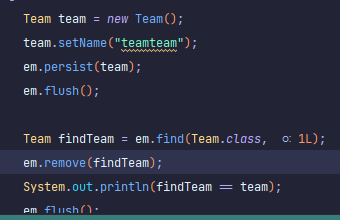

위의 코드와 실행 결과로 살펴보면 알 수 있다. team을 persist를 통해 insert 한 후에 find로 찾아온다. 그후 찾아온 findTeam을 em.remove 하게 되면 team과 findTeam은 동일성에 의해 동일한 엔티티이므로 delete문이 정상적으로 실행되는 것을 확인할 수 있다. == 연산의 결과도 참이 된다.
관련글
자바 ORM 표준 JPA 프로그래밍 - 기본편 - 인프런 | 강의
JPA를 처음 접하거나, 실무에서 JPA를 사용하지만 기본 이론이 부족하신 분들이 JPA의 기본 이론을 탄탄하게 학습해서 초보자도 실무에서 자신있게 JPA를 사용할 수 있습니다., 본 강의는 자바 백엔
www.inflearn.com
'백엔드 > JPA' 카테고리의 다른 글
| JPA 값타입 (0) | 2021.08.08 |
|---|---|
| JPA 프록시와 영속성 전이 (0) | 2021.08.06 |
| JPA 엔티티 매핑2 (0) | 2021.08.05 |
| JPA 엔티티 매핑1 (0) | 2021.07.29 |
| 스프링부트 테스트 영속성과 JPQL (0) | 2021.07.27 |


